



Intelligenz-Wunderwelt: Wer daran glaubt, darf sich nicht wundern
(Red.) Das Thema «Künstliche Intelligenz» beschäftigt uns alle, da die Befürchtung besteht, dass künftig wichtige Entscheidungen nicht mehr von Menschen, sondern von „intelligenten“ Maschinen gefällt werden, wie dies Peter Vonnahme in einem Artikel hier auf Globalbridge.ch zum Ausdruck gebracht hat. Von technischer Seite kommt jetzt Widerspruch, dem wir uns nicht verschließen wollen. Siehe dazu aber auch ganz unten bei den Anmerkungen zum Autor des hier folgenden Artikels die Anmerkung der Redaktion von Globalbridge.ch. (cm)
(RF) Unter dem Titel »Künstliche Intelligenz — Wir verlieren die Kontrolle« veröffentlichte Peter Vonnahme auf Globalbridge.ch einen Text, den er mit der Absicht einer eindringlichen Warnung vor dieser Technik abgefasst hatte. Die KI ist in der Tat ein wichtiges Thema, das der kritischen Würdigung bedarf. Der genannte Artikel genügt jedoch den an eine solche zu stellenden Anforderungen in keiner Weise. Das Ausmalen diffuser Bedrohungsszenarien, die phantastischen Fähigkeiten auf KI-Systeme projizieren, ist wenig hilfreich, ja sogar gefährlich. Der nachfolgende Text, der am 27. Juni 2024 auf Makroskop erschienen ist, versucht dagegen, ein realistisches Bild der Technik zu entwerfen. Da er hier als Antwort auf Peter Vonnahme auftritt, seien einleitend einige Anknüpfungspunkte aufgeführt.
Um mit dem Grundsätzlichen zu beginnen: die Künstliche Intelligenz gibt es nicht. Was es gab und gibt, sind diverse Ansätze und Forschungsprogramme, die auf spezifische Ziele ausgerichtet, doch, mit wenigen Ausnahmen, selbst diese bisher nicht erreicht haben und von einer Artificial General Intelligence weit entfernt sind. Das, was heute unter dem Terminus ›Maschinenlernen‹ stattfindet, hat mit Lernen im herkömmlichen Sinne nichts zu tun. Es handelt sich um ein Optimierungsproblem, bei dem es darum geht, eine durch Datenpunkte gegebene Relation durch eine geeignet konfigurierte Software zu approximieren — wobei der größte und äußerst energieintensive Aufwand in der Bestimmung der entsprechenden Parameter liegt.
Dabei wird, um aus Vonnahmes Text zu zitieren, weder »die Gesamtheit des vorhandenen Wissens« verknüpft, noch kann davon die Rede sein, dass »die KI […] dank ihrer enormen Lernfähigkeit selbständig nach Wegen suchen [wird], wie sie ihre Vormachtstellung sichern und ausbauen kann«, dass »die KI […] vermutlich bereits heute durch Ausschöpfung aller verfügbaren Quellen „erkannt“ [hat], dass der Mensch im Begriff ist, seine Lebensgrundlagen auf der Erde zu zerstören und dass sein Verstand und/oder seine Moral nicht ausreichen werden, das Untergangsszenario rechtzeitig zu unterbrechen«, oder gar, dass »die KI […] das Geschehen unaufhörlich [beobachtet (berechnet)] und sie […] im Stillen weiter [wächst]«. Eine solche Dämonisierung verhindert gerade die notwendige rationale und kritische — was auch heißen muss: hinreichend präzise und informierte — Auseinandersetzung mit dieser Technik, der tatsächlich Gefahren innewohnen, denen in dieser Weise nicht zu begegnen ist. Im Gegenteil: ihre Dämonisierung macht kopflos — was den Meistern aus dem Silicon Valley, die sie beständig unter dem Vorwand betreiben, vor ihr zu warnen, anscheinend recht ist.
Der Computer, der sich gegen den Menschen auflehnt, weil ihm der zu unvernünftig, zu wenig intelligent, zu zurückgeblieben erscheint, ist Science Fiction. Wer denkt dabei nicht an HAL aus Stanley Kubricks 2001. Seither hat das Thema einen dringlicheren Charakter angenommen, nicht weil es stärkere Anzeichen für eine Revolte der Computer gäbe, sondern weil eine Ideologie an Einfluss gewinnt, die die »Antiquiertheit des Menschen« offensiv zum Thema macht und letzteren abschaffen will: der Transhumanismus, der nicht zuletzt unter Tech-Milliardären und ihren Hofnarren, den Polit-Influenzern wie WEF-Gründer Klaus Schwab und Pop-Historiker Yuval Noah Harari Anhänger hat. Indem Vonnahme eine KI phantasiert, die den ökologisch uneinsichtigen Menschen beseitigt, macht er sie zum sintflutlichen Ersatzgott, der dadurch eine von ihm imaginierte kosmische Ordnung wiederherstellt. Eine solche Öko-Techno-Theologie scheint gerade populär zu sein, bietet aber weder zur treffenden Einschätzung der anstehenden Gefahren und Aufgaben noch zum Umgang mit ihnen Ansätze.
Peter Vonnahme hängt unangemessenen Vorstellung von der Evolution des Lebens und insbesondere der des Menschen an. So ist die Annahme, Wahrnehmung, Intelligenz und Lernen, schließlich »die Fähigkeit, Sinnvolles vom Schädlichen zu trennen und danach zu handeln«, seien allein dem Menschen gegeben, schlecht begründet. Tatsächlich gehören diese zu jeder Art von Leben. Schon Einzeller verfügen darüber. Viel spricht dafür, dass Maschinen dies nie tun werden. Wenn die Evolution über einen gegebenen Stand hinausschreitet, wird Bewährtes nicht vernichtet, sondern aufbewahrt, kopiert und angeeignet: der Neandertaler und der Denisova-Mensch haben unter den Eurasiern von Porto bis Tokyo eine genetische Erbschaft hinterlassen, die eine Anpassung an kalte Klimate erleichtert. Der größte Teil des menschlichen Genoms stammt von Einzellern und wirbellosen Tieren. Auch das Abschreiben von Texten hat — bestes und immer noch nachahmungswürdiges Beispiel dafür Karl Marx im Reading Room des British Museum — auch Jahrhunderte nach der Durchsetzung des Buchdrucks noch seinen Sinn und der Laptop ist die Reiseschreibmaschine und noch viel mehr. Uninformiertes, schematisches Denken stellt eines der größten Hindernisse bei der Auseinandersetzung mit den Herausforderungen von Wissenschaft und Technik dar.
Ab hier Zitat Rainer Fischbach in der Zeitschrift Makroskop:
Die mit der Künstlichen Intelligenz verbundene Gefahr liegt nicht darin, dass diese uns einmal beherrschen würde. Sondern in Projektionen, die ihr Leistungen zutraut, die sie nicht zu erbringen vermag.
Wer in der Mitte des vorigen Jahrhunderts geboren wurde und die Gelegenheit hatte, technische Entwicklungen und deren medial konstruierte Bilder über Jahrzehnte zu verfolgen, sieht sich heute mit Déja-vu-Erlebnissen konfrontiert: „Menschen, die sich und ihren Selbstwert über ihre Arbeit definieren, werden künftig – so scheint es – keine Arbeit finden“, war kürzlich auf MAKROSKOP zu lesen.
Die Ankündigungen, dass Automaten uns bald arbeitslos machten, ist seit mehr als einem halben Jahrhundert zu vernehmen. Und wenn man sich die Mühe macht, noch weiter zurückzuschauen, findet man noch mehr davon. In den 1980ern war es auch schon einmal die Künstliche Intelligenz (KI), die in Gestalt sogenannter Wissensbasierter Systeme (Knowledge-based Systems, KBS) Ingenieure, Ärzte und Wissenschaftler ersetzen sollte. Jetzt ist es wieder so weit: „Zunächst einmal aber werden Wissensarbeiter durch KI ersetzt, die Routinen bedienen“, so der erwähnte Artikel, der allerdings offen lässt, welche „Routinen“ damit gemeint sind. Humanoide Roboter, so ist dort weiter zu lesen, „[läuten] im Verbund mit generativen Fertigungstechnologien […] die finale industrielle Revolution ein“.
Die großen Umwälzungen wollten sich schon damals nicht einstellen. KBS erwiesen sich in wenigen Gebieten, auf denen das relevante Wissen weitgehend schon explizit formuliert und deshalb auch leicht formalisierbar war, weniger als Ersatz, sondern mehr als Unterstützung für qualifizierte Arbeit – zum Beispiel in der Chemie. Zwei Sachverhalte verhinderten ihren Erfolg: Erstens liegt das Wissen von Experten zu einem großen Teil nicht explizit vor, sondern ist solchen meist nur implizit und situativ verfügbar. Zweitens helfen deduktive Systeme wie die KBS in den meisten Situationen nicht, in denen Expertise gefragt ist.
Gegeben ist meist ein Fall – etwa in der Medizin eine Symptomatik, in der Instandhaltung ein Geräusch, eine verminderte oder ausgefallene Funktion einer Maschine etc. – der aufzuklären ist. Zudem gibt es eine Vielzahl möglicher Ursachen, die einzeln oder zusammenwirkend für den vorliegenden Fall verantwortlich sein könnten. Den Experten zeichnet aus, dass er intuitiv die unter den gegebenen Umständen wahrscheinlichsten Ursachen erkennt und auch um die Wege weiß, auf denen er seine Hypothesen überprüfen kann.
Diese Form des Denkens und die Art des Wissens, das es involviert, sind – wenn auch Deduktion darin eine untergeordnete Rolle spielt – in ihrem Kern nicht deduktiv und schwer oder nicht formalisierbar.[1] Zum verständigen Einsatz von Deduktion gehört zudem die Wahrnehmung der Situationen, in denen sie mit der Realität kollidiert: dass Vögel fliegen können und Raben in deren Familie gehören, ist weithin bekannt. Doch die Annahme, dass der Rabe Max fliegen könne, erweist sich als falsch, wenn Max in einem engen Käfig sitzt oder einen gebrochenen Flügel hat.[2]
Das Pentagon setzte Millionen in den Sand
Das Konzept der KBS war nicht das einzige, das trotz Schlüssigkeit innerhalb einer abstrakten Modellwelt an der Realität scheiterte. Nicht besser als den KBS in den 1980ern war es schon in den 1960ern den Versuchen ergangen, Übersetzungen auf Basis der damals fortgeschrittensten linguistischen Theorie, der durch Noam Chomsky formulierten generativen Transformationsgrammatik, automatisch auszuführen. Zwar fand die Transformationsgrammatik im Reich der künstlichen formalen Sprachen – solche für die Programmierung, für mathematische und logische Kalküle – erfolgreichen Einsatz, nicht aber in dem natürlicher Sprachen. Schuld am Scheitern waren deren Irregularität, Ambiguität und Idiomatik. Die vielen Millionen, die das Pentagon in der Hoffnung auf rasch verfügbare Übersetzungen aus dem Russischen in einschlägige Projekte investiert hatte, mussten abgeschrieben werden.
Erste bedingte Erfolge gab es auf diesem Gebiet im letzten Jahrzehnt auf der Basis anderer Ansätze. Diese verzichteten darauf, Syntax und Semantik natürlicher Sprachen zu verstehen: Entscheidend ist das statistische Profil von Wörtern und Sätzen. An die Stelle von syntaktischer Struktur und Bedeutung tritt die Einbettung in einen Wahrscheinlichkeitsraum von hunderten und inzwischen auch schon zig tausenden Dimensionen, in dem Ähnlichkeit, Analogie und Abfolge sich durch Vektordistanzen abbilden. In deren Bereich gibt es passable Übersetzungen und produzieren die generativen Systeme wie ChatGPT, die ebenfalls auf dieser Basis arbeiten, Auskünfte, inzwischen auch Bilder und Videosequenzen, die oberflächlich so ähnlich aussehen wie menschliche Hervorbringungen. Doch sie können auch falsch bzw. völlig irreal oder sogar schlicht idiotisch sein.[3] Solche Systeme „verstehen“ nicht das Geringste – weder logische Operationen, Präpositionen oder gar die Gesetze der Physik, um von kulturellen Normen und Überlieferungen ganz zu schweigen. Wenn es um kritische Details geht, sollte man darauf nicht vertrauen.
Die Variante der KI, die als Spitzenprodukte solche Dinge hervorbringt und dadurch große Aufmerksamkeit hervorruft, ist im Prinzip nicht neu: kein epochaler Durchbruch hat sie hervorgebracht, sondern sie ist aus dem Zusammenfluss einer Reihe von Entwicklungen hervorgegangen. Während die mathematische Statistik schon seit gut 180 Jahren existiert, wurden die Neuronalen Netze vor sieben Jahrzehnten erfunden. Die Idee, solche hintereinander zu tiefen Netzen zu schalten und ihre Parameter anzupassen, bis die Funktion, die sie implementieren, das angezielte Input/Output-Verhalten aufweist,[4] kam vor sechs Jahrzehnten auf. Letztlich waren es – neben der durch die Internetplattformen gegebene Möglichkeit, Daten massenhaft zu produzieren –, Fortschritte in der Leistung und der Erschwinglichkeit von Rechnerhardware, die die Realisierung jener Konzepte ermöglichten. Entscheidend waren dabei das Aufkommen von paralleler, auf Vektoroperationen spezialisierter Hardware, das durch massenhafte Anwendungen von Computergraphik, insbesondere in Spielen und Animationsvideos getrieben wurde. Auf diese Weise konnte Nvidia, der führende Hersteller von Graphikprozessoren, diese Rolle auf die KI ausdehnen.
Maschinenlernen ist nicht nur mit Unsicherheit behaftet
Man spricht im Zusammenhang dieser Technik von Maschinenlernen (ML). Sinnvoller wäre es aber, von Anpassung bzw. Konditionierung zu sprechen, die in der sogenannten Trainingsphase stattfindet, die dem Einsatz der Systeme vorausgeht. Ihr Verständnis wird verhindert, indem man geheimnisvolle Fähigkeiten in sie projiziert. So zum Beispiel eine Stellungnahme des Deutschen Ethikrats, in der die Rede ist von einer „Trainingsphase, in der ein Algorithmus sein Modell zur Mustererkennung durch wiederholte Analyse von Trainingsdaten aufbaut und verfeinert“.[5] Doch findet dabei keine „Analyse“ statt, die in den Daten verborgene Zusammenhänge aufdecken würde, sondern eine bloße Imitation der dort sichtbaren Relation von Input und Output, die durch die Erwartung motiviert ist, dadurch auch den Output für noch unbekannte Werte des Inputs zu finden.
Diese Imitation erfolgt dadurch, dass die Parameter einer zum Beispiel durch ein tiefes Neuronales Netz repräsentierten Funktion schrittweise variiert werden, bis diese die Trainingsdaten in hinreichender Näherung wiedergibt. Dazu müssen oft Millionen und bei einem sogenannten Large Language Model (LLM), wie es ChatGPT zugrunde liegt, sogar Milliarden von Parametern wiederholt angepasst werden. Maschinenlernen ist deshalb ein energieintensives Geschäft.[6] Doch geht es dabei um ein klassisches Optimierungsproblem, das mit Analyse oder gar Verständnis nichts zu tun hat.
Die Rede von „lernenden Algorithmen“ geht an der Sache vorbei: Algorithmen sind feststehende Rechenverfahren. Sie lernen nichts. Im vorliegenden Zusammenhang gibt es eine überschaubare Anzahl von Algorithmen, die zum Beispiel im Fall der tiefen Neuronalen Netze dazu dienen, deren Funktion für einen Input auszuwerten oder aus der Abweichung vom angezielten Verhalten Anpassungen für die Parameter zu berechnen. Wesentlich ist dabei, dass die eingesetzten Algorithmen mit der jeweiligen Aufgabe nichts zu tun haben. Das macht den fundamentalen Unterschied zu klassischen algorithmischen Lösungen – auch in der herkömmlichen KI – aus, die immer von einem strukturellen Modell des Gegenstands ausgehen. Das Verhalten eines Neuronalen Netzes ist allein durch seine Architektur und seine Parameter bestimmt – wobei es für beides keine profunde Theorie gibt. Die Architektur beruht auf Erfahrungswerten und die Wahl der Parameter eben auf gezieltem Probieren.
Das Maschinenlernen ist nicht nur mit der Unsicherheit behaftet, die allen induktiven Techniken zu eigen ist, also der Ungewissheit darüber, wie weit die Imitation der Input-Output-Relation über den Bereich der Trainingsdaten extrapolierbar ist. Sondern auch mit einem mangelhaften Wissen darüber, wasgenau beim Training in Beziehung gesetzt wurde. Letzteres betrifft vor allem die Identifikation bzw. Klassifikation von Objekten in komplexen Datengebilden wie Bildern.
Wurde zum Beispiel ein System trainiert, um unterschiedliche Früchte zu erkennen, können ungewöhnliche Exemplare oder Sorten der Identifikation entgehen, wenn sie von den in den Trainingsdaten enthaltenen zu stark abweichen. Im Prinzip gleichartig, doch von ungleich größerer Tragweite war das Versagen eines Systems, das dunkelhäutige Menschen als Gorillas einordnete.
Das war die Folge von Trainingsdaten, die der Varianz des menschlichen Phänotypus nicht Rechnung trugen. Ein deutlich schwerer aufzuklärendes Versagen resultiert daraus, dass die zu identifizierende Klasse von Objekten mit einem zufälligen Merkmal oder Begleiter assoziiert wird. Ein System, das Panzer erkennen sollte, erwies sich im Einsatz dazu unfähig, weil die wahrscheinlich aus Werbematerial entnommenen Bilder für das Training die Panzer immer nur in schönstem Licht zeigten. Eine etwas andere Situation kann sich ergeben, wenn Objekte in der Realität in Begleitung weiterer Objekte oder durch zufällige Merkmale verändert auftreten und deshalb nicht erkannt werden.
Das stellt zum Beispiel bei selbstfahrenden Autos eine ernste Gefahr dar, etwa wenn ein Stoppschild nicht erkannt wird, weil jemand ein Smiley darauf gemalt hat – eine Lage, deren manche Utopisten Herr werden wollen, indem sie visuelle Zeichen durch elektronische ersetzen und alle Verkehrsteilnehmer mit identifizierenden und Bewegungsdaten preisgebenden Sendern versehen.
Genauigkeit, die keine Basis hat
Gerade das fahrerlose Automobil bietet sich als Lehrstück zu überschießenden Erwartungen an: Vor zehn Jahren war überall zu hören, dass es in naher Zukunft in großen Zahlen die Straßen bevölkern würde, dass insbesondere fahrerlose Taxis und Kleinbusse bald den öffentlichen Verkehr übernähmen. Nicht nur, dass sich nichts davon abzeichnet. Auch die großen Spieler – gleichgültig, ob aus der IT oder aus der Automobilindustrie – haben ihr Engagement deutlich reduziert oder ganz aufgegeben. Dies, nachdem ca. 100 Milliarden Dollar versenkt wurden und nicht wenige Verkehrsplaner sich von der Erwartung baldiger Verwirklichung der in zahllosen Bildern und Videos ausgemalten Szenarien leiten ließen. Technokratische Utopien formen Politik und lenken Ressourcen lange bevor und selbst wenn sie nie Realität werden. Stimmen aus der Finanzwelt weisen derzeit darauf hin, dass die anschwellenden Finanzströme in Richtung KI eine Blase erzeugen könnten, die – analog zum dot.com-Crash von 2000 – in einem KI-Crash enden könnte.[7]
Vom Versagen überschießender und nicht zu haltender Versprechen werden derzeit insbesondere die Biowissenschaften heimgesucht. Eine wachsende Anzahl von Resultaten, selbst in peer-reviewed Journals publizierte, lassen sich nicht reproduzieren.[8] Viele Anwendungen leiden unter dem Problem, das im Zusammenhang der „Panzer in schönstem Licht“ skizziert wurde: die Ergebnisse lassen sich auch produzieren, wenn man etwa aus den verwendeten Bilddaten lediglich unwichtige Ausschnitte benutzt, in denen das Merkmal bzw. Objekt, das erkannt werden sollte, nicht vorkommt, während die damit trainierten Systeme vor unbekannten Daten weitgehend versagen. Hier scheint sich eine Umwälzung ohne solides Fundament zu vollziehen.
Ein Fehler von großer Tragweite besteht im Overfitting, das heißt der Neigung, Systeme viel zu genau an die Trainingsdaten anzupassen. Auf diese Weise bildet man hauptsächlich das Rauschen in den Daten ab und täuscht eine Genauigkeit vor, die keine Basis hat.[9] Mit großem Aufwand gebaute Modelle, die zum Beispiel aus Mustern geologischer Aktivität Erdbeben vorhersagen sollten, mussten aufgegeben werden, weil sie sehr genau vergangene, doch zukünftige Erdbeben überhaupt nicht vorherzusagen wussten.
Ein Dilemma resultiert aus der statistischen Natur des Maschinenlernens. Soll ein System den Gegenstandsbereich in Klassen einteilen, liefert es einen Vektor, der eine Wahrscheinlichkeitsverteilung repräsentiert. Das heißt, dessen Felder haben die Summe eins und geben für jede Klasse die Wahrscheinlichkeit an, dass der betreffende Gegenstand – ein Kundenprofil, eine bildliche Darstellung, ein akustisches Signal etc. – in die jeweilige Klasse fällt. Geht es um eine binäre Entscheidung, genügt eine Zahl zwischen null und eins. Die Frage ist, wo man die Schwelle ansetzt, an der der Umschlag von null auf eins stattfindet. Ja niedriger man sie wählt, desto vollständiger wird man alle tatsächlich positiven Fälle erfassen – allerdings um den Preis einer wachsenden Anzahl falsch positiver.
In dem Schaubild unten erscheint dies als immer steilerer Anstieg der False Positive Rate (FPR) mit wachsender True Positive Rate (TPR). Von einem bestimmten Punkt an wird man für jeden zusätzlich erkannten wahr positiven Fall mehr als einen falsch positiven bekommen. In vielen Anwendungen, insbesondere in der Technik, sind jedoch weder nicht erkannte positive Fälle noch eine signifikante Anzahl von falsch positiven akzeptabel. Wenn zum Beispiel ein System, das Anzeichen von Schäden in einer Anlage erkennen soll, ernste Fälle nicht meldet, kann das sehr teuer werden. Umgekehrt sind aber auch zu viele blinde Alarme nicht tolerabel.
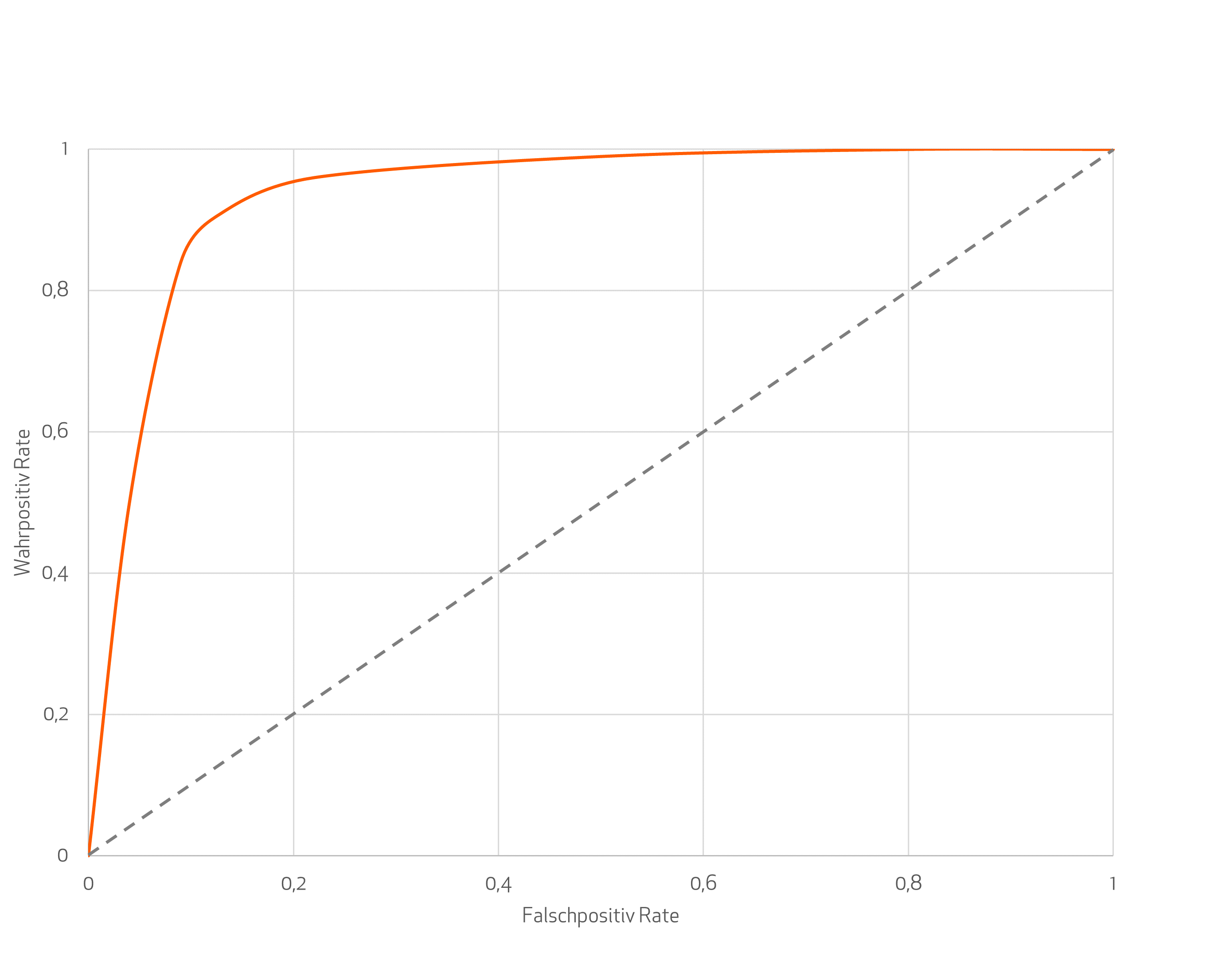
Das Schaubild stellt die sogenannte ROC-Kurve dar. ROC ist die Abkürzung für Receiver Operation Characteristic – ein Begriff, der auf seinen Ursprung in der Radartechnik hinweist. Dort stieß man auf den Sachverhalt, dass die Steigerung der TPR durch Absenkung der Schwelle der empfangenen Leistung für die Detektion von Objekten zu einem Anstieg der FPR führt – eine Verfahrensweise, die die Welt an den Rand eines Atomkrieges führen kann, wenn etwa ein Schwarm Wildgänse für ein Bombergeschwader gehalten wird.
Ähnliches geschah jüngst in der Medizin. Indem man den Vervielfältigungsfaktor der DNA in die Milliarden und Billionen trieb,[10] sank die Schwelle für das Ansprechen des PCR-Tests so weit herab, dass die Zahl der falsch positiven die der wahr positiven Resultate überstieg.[11] Auf diese Weise erhielt man eine sogenannte Pandemie. Dabei setzte sich die Verletzung methodischer Sorgfalt in einem Verstoß gegen die Prinzipien ärztlichen Handelns fort. Schon Georges Canguilhem hatte betont: „wenn man der Ansicht ist, dass die anatomische und histologische Beobachtung, der physiologische Test oder die bakteriologische Prüfung Methoden darstellen, dank derer man auf wissenschaftlichem Wege (…) eine Krankheitsdiagnose stellen kann, sitzt man unseres Erachtens einem philosophisch äußerst schwerwiegenden und therapeutisch verheerenden Missverständnis auf“.[12]
Die Meinungsfreiheit stirbt lautlos im Verborgenen
Der PCR-Test illustriert einen methodischen Fehler, der mit dem Einsatz von maschinellem Lernen, sowohl in der Medizin als auch in anderen Bereichen, zunehmend auftreten dürfte. Infolge des Digital Services Act (DSA) der EU dürfte eine Flut von potenziell staatsgefährdenden und daher automatisch gelöschten Äußerungen auf diversen Internetplattformen aufkommen. Um den zu erwartenden Sanktionen zuvorzukommen, werden die Plattformbetreiber die Schwelle für die Meldung von Verstößen durch ihre Inhaltserkennungssysteme möglichst niedrig ansetzen. Die Meinungsfreiheit stirbt so lautlos im Verborgenen.
Die mit der Proliferation von KI-Systemen verbundene Gefahr liegt nicht darin, dass diese tatsächlich Superintelligenz erwerben und uns beherrschen würden. Die Gefahr liegt in Projektionen, die ihnen Leistungen zutrauen, die sie nicht zu erbringen vermögen. Indem man sich immer mehr auf sie verlässt, erlangen sie epistemische Macht. Sie definieren, welche Äußerungen gelöscht werden und welche Sprache noch zulässig ist. Wer in der Schule abschreibt, verzichtet darauf, etwas zu lernen; wer seine Texte überwiegend von ChatGPT verfassen lässt, lernt nicht nur nichts, sondern gibt die Autorität zur Beschreibung der Welt an ein System ab, das in dem Maße, indem es diese Autorität übernimmt, selbstrefentiell wird. Schon die hechelnde Jagd nach immer mehr Daten, die angeblich zur grenzenlosen Steigerung der Fähigkeiten von KI-Systemen führe, übersieht nicht nur, dass deren Leistungen prinzipiellen Beschränkungen und damit einer Tendenz zur Sättigung unterliegen. Sie fällt auch schon der Täuschung zum Opfer, Daten seien objektiv gegeben. Daten sind immer gemacht und durch die modellistische Sicht ihrer Macher geformt. Sie sind nicht mit der Wirklichkeit identisch.[13]
Vor diesem Hintergrund wären die Pfade, auf die sich die Politik derzeit begibt, ebenso zu hinterfragen, wie der Enthusiasmus, der sie zu treiben scheint. Es gilt einerseits die Grenzen der Technik zur Kenntnis zu nehmen und andererseits überlegt Felder zu identifizieren, auf denen sie von Nutzen sein könnte:
„Deep Learning, das im Grunde eine Technik zur Erkennung von Mustern ist, funktioniert am besten, wenn wir nur grobe Ergebnisse benötigen, bei denen der Einsatz gering und perfekte Ergebnisse optional sind.“[14]
Will Deutschland – solange die Industrie noch eine Rolle spielt und der Dienstleistungssektor noch hinreichende Expertise bereithält – erfolgreich Anwendungen entwickeln, kann dies nicht nach dem Modell der Internet-Plattformen geschehen, bei dem massenhaft Daten gesammelt und die Markierungsarbeit von Clickworkern erledigt wird. Stattdessen müssen sachkundige Anwender bereits in der Entwicklungsphase einbezogen und die organisatorischen Strukturen und Abläufe angepasst werden.[15] Dies und viel Aufmerksamkeit, Sorgfalt sowie Geduld sind notwendig, um die Unvollkommenheiten der Technik zu kompensieren und die damit verbundenen Risiken zu minimieren.
Auch all die seit Jahrzehnten immer wieder ihre verführende Wirkung entfaltenden Träume gehören auf den Prüfstand: dass der Computer die durchgängige Automatisierung der Produktion erlauben und ganz nebenbei die bisher höchst unvollständig gelösten Aufgaben der gesellschaftlichen Planung erledigen könnte.[16] Mit Maschinenlernen, so eine verbreitete Hoffnung, müsste das doch endlich gehen.
Auch hier erliegen viele der Magie des Wortes „lernen“. Doch ein solches System kann nicht „lernen“, die richtigen planerischen Entscheidungen zu treffen. Die Idealwelt, in der der Markt eine optimale Güterverteilung erreicht, basiert auf dezentralen Regelkreisen, in denen Zielfindung, Information und Entscheidung ineinandergreifen. Es ist bekannt, dass dies in einer Welt mit wirtschaftlichen Machtasymmetrien und im Umgang mit Gemeingütern nicht funktioniert. Obgleich steuernde Eingriffe also notwendig sind, bleibt die Kunst der erforderlichen Planung unterentwickelt.
Informationstechnologie könnte zwar präzisere Auskünfte über verfügbare Güter und das Verhalten der Wirtschaftssubjekte liefern, ist jedoch mit der Abschätzung des Potenzials und der Risiken technischer Entwicklungen sowie der Ziel- und Entscheidungsfindung überfordert. Auch Maschinenlernen kann nicht bestimmen, was wir produzieren, wie wir es verteilen oder welche Innovationen wir verfolgen sollen. Dafür bleibt unsere menschliche Intelligenz weiterhin unverzichtbar.
Zum Autor: «Rainer Fischbach war Jahrzehnte mit der Konstruktion industrieller Softwaresysteme sowie betrieblich und als Dozent mit der Ausbildung Technischer Informatiker beschäftigt. Er forschte zur Planungstheorie, zur allgemeinen Technologie und zur Technikfolgenabschätzung.» (Zitat Makroskop) / Die Redaktion Globalbridge dankt Rainer Fischbach für seine offensichtlich fachkundige Information, wird aber darauf verzichten, die Diskussion zur Künstlichen Intelligenz in dieser spezifischen, aber leider eben schwer verständlichen Fachsprache der involvierten Techniker weiterzuführen – nicht aus Desinteresse, aber aus der journalistischen Verpflichtung heraus, auch schwierige Diskussionen im Hinblick auf bevorstehende demokratische Entscheidungen in gemeinverständlicher Sprache zu führen.
Fussnoten:
[1] Die Probleme der Abduktion, wie der Logiker Charles Sanders Peirce diese Form des Denkens genannt hat, diskutiert ausführlich Erik J. Larson: The Myth of Artificial Intelligence: Why Computers Can’t Think the Way We Do. Cambridge MA: Harvard University Press, 2021, Teil II.
[2] Eine genauere Diskussion der epistemischen Probleme bietet neben dem genannten Werk von Larson Rainer Fischbach: Big data — big confusion: Weshalb es noch immer keine künstliche Intelligenz gibt. Berliner Debatte Initial 1, 2020. 136–147.
[3] Gary Marcus: OpenAI™’s new text-to-video app is impressive, at first sight. But those physics glitches…. Bulletin of the Atomic Scientists, 16. Februar 2024.
[4] Dazu findet die sog. Backpropagation Anwendung. Dieser Algorithmus vermag aus der Abweichung vom angezielten Verhalten immer wieder eine Korrektur für die Parameter zu errechnen, bis eine hinreichende Annäherung an das gewünschte Verhalten erreicht ist.
[5] Mensch und Maschine – Herausforderungen durch Künstliche Intelligenz. Berlin: Deutscher Ethikrat, 20. März 2023.
[6]Das bremst auch die angestrebte Abkehr von fossilen Brennstoffen. Dazu Myles McCormick, Jamie Smyth, Amanda Chu: AI revolution will be boon for natural gas, say fossil fuel bosses. Financial Times, 1. April 2024.
[7] Dazu Grant Gross: Generative AI gold rush drives IT spending — with payoff in question. CIO, 19. April 2024; Henry Mance: AI keeps going wrong. What if it can’t be fixed? Financial Times, 6. April 2024 und John Thornhill: Huge AI funding leads to hype and ›grifting‹, warns DeepMind’s Demis Hassabis. Financial Times, 31. März 2024.
[8] Elizabeth Gibney: Could machine learning fuel a reproducibility crisis in science? Nature 608, 250–251, 26. Juli 2022; Emily Sohn: The reproducibility issues that haunt health-care AI. Nature 613, 402–403, 12. Januar 2023.
[9] Die Problematik des Overfitting ist ausführlich mit Beispielen dargelegt in Nate Silver: The Signal and the Noise: The Art and Science of Prediction. New York NY: Penguin, 2012, Kap. 5.
[10] Da die PCR nur DNA vervielfältigen kann, ist zum Nachweis von Coronaviren zunächst die reverse Transkription von deren RNA in DNA erforderlich. Allerdings bedeutet das Vorhandensein der RNA noch nicht das von vermehrungsfähigen Viren oder gar das Vorliegen einer Erkrankung. Dazu mehr in Rainer Fischbach: Ein Virus zum Beispiel: Wie eine Gesellschaft Vernunft und Humanität verlor — und wie sie wiederzugewinnen wären. Düren: Shaker Media, 2023, 83–89.
[11] Auf diese Problematik wiesen schon früh hin Rita Jaafar, Bernard La Scola et al. (2020): Correlation Between 3790 Quantitative Polymerase Chain Reaction–Positives Samples and Positive Cell Cultures, Including 1941 Severe Acute Respiratory Syndrome Coronavirus 2 Isolates. Clinical Infectious Diseases72(11), e932–933, 28. September 2020.
[12] Georges Canguilhem: Das Normale und das Pathologische. Neuausgabe, Berlin: August, 2012 [1943], 238–239.
[13] Ausführlich dazu Rainer Fischbach: Modellwelten, Weltmodelle und smarte Objekte. In: Jörg Pohle, Klaus Lenk, Rainer Fischbach (Hrsg.): Die gesellschaftliche Macht digitaler Technologien: Zwischen Wellen technologischen Überschwangs und den Mühen der Ebene. Marburg: Metropolis, 2024, 141–198.
[14] Gary Marcus: Deep Learning Is Hitting a Wall. Nautilus, 10. März 2022.
[15] Thomas Herrmann, Sabine Pfeiffer: Keeping the Organization in the Loop: A Socio-Technical Extension of Human-Centered Artificial Intelligence. AI & Society 38, 2023, 1523–1542.
[16] Genauer diskutiert dies Rainer Fischbach: Die schöne Utopie: Paul Mason, der Postkapitalismus und der Traum vom grenzenlosen Überfluss. Köln: PapyRossa, 2017 (Neue Kleine Bibliothek; 238).